北京,2016年7月26日——
为了进一步完善大数据平台,企业级基础云服务商青云QingCloud(qingcloud.com)日前宣布新增分布式实时计算系统Storm和基于Hadoop的数据仓库工具Hive,这是继月初推出Elasticsearch全文搜索引擎服务后QingCloud推出的又一重要功能。随着数据在企业商业决策和产品功能中起到的作用越来越重要,大数据技术正在越来越多的企业中发挥出更大价值。QingCloud正在不断完善大数据平台,帮助用户降低技术门槛。目前,两个新功能已经分别在QingCloud控制台的大数据平台和映像市场上线。

QingCloud Storm功能上线
Storm是一个开源的分布式实时计算系统,通常被比作"实时的Hadoop"。Storm为实时计算提供了一些简单优美的原语,支持多种编程语言,并内建流式窗口API及分布式缓存API,极大简化了流式数据处理过程。Storm不仅高可靠、易扩展,而且处理速度极快,每个计算节点每秒能处理上百万条元组信息(Tuple),因此常被用于实时分析、在线机器学习、连续计算、分布式RPC、ETL等。QingCloud提供的Storm 集群采用Master/Slave 架构,提供了在线伸缩、监控告警等功能,帮助用户更好地管理集群。
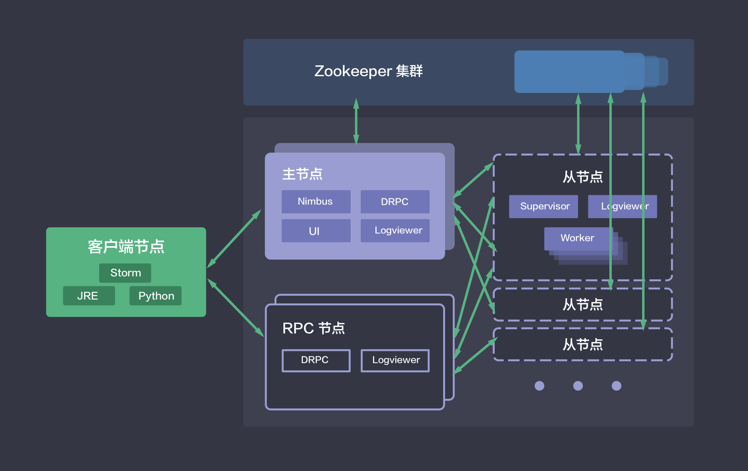
QingCloud Storm集群架构图
通常包括Storm在内的大数据平台的运维都是非常繁琐的,但在QingCloud上,用户可以在2到3分钟创建一个Storm集群。集群支持横向与纵向在线伸缩,还提供了监控告警等功能,使得管理集群异常方便。集群运行于100%二层隔离的私有网络内,结合QingCloud提供的高性能硬盘,在保障高性能的同时兼顾用户的数据安全。
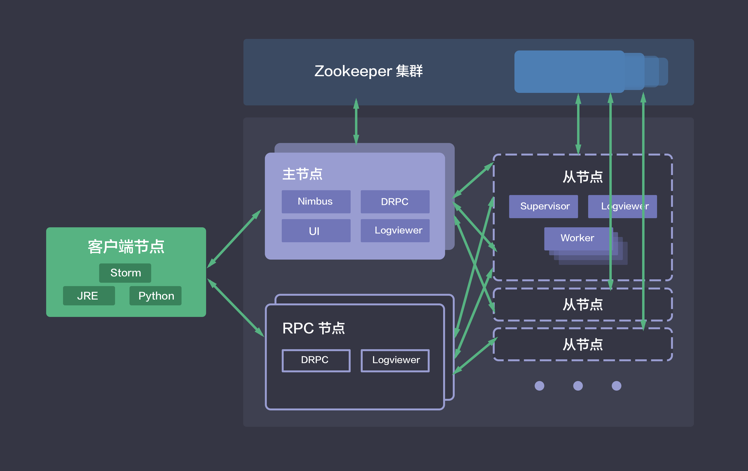
QingCloud Hive服务架构图
Hive是基于Hadoop的一个主流的针对海量数据做离线分析的数据仓库,可以将结构化的数据文件映射为数据库表,并提供简洁的类SQL(称为HQL)查询功能,将HQL语句转换为MapReduce任务后运行。 其优点是学习成本低,可通过HQL语句快速实现简单的MapReduce统计,大部分场景不必开发专门的MapReduce应用,十分适合基于数据仓库的统计分析。另外,也可通过MapReduce开发扩展新功能函数。
QingCloud提供的Hive映像包含了Hive Client和Hive Server的所有功能。用户在Hive Client端发起HQL任务,通过Hive Server实现HQL到MapReduce任务的转换,然后调用Hadoop集群执行。在QingCloud上,用户可以在2到3分钟内创建一个Hive服务,并完成与其他大数据集群连接的配置。Hive服务支持纵向在线伸缩, 提供了监控告警等功能,使得服务管理非常方便。
青云QingCloud CTO甘泉(Reno Gan)表示:“Storm、Hive服务的推出标志着QingCloud大数据基础平台的进一步完善,结合已经推出的Spark、Hadoop、ZooKeeper、消息队列(Kafka)、Elasticsearch等服务,QingCloud的大数据平台服务已经能够满足用户的各种需求。很快我们还将会上线HBase存储集群服务,提升整个大数据生命周期使用效率的各类平台管理服务——包括但不限于日志服务、计算引擎灵活切换、对象存储集成、服务编排等,以及基于主流机器学习平台的智能分析服务。此外,全新的容器技术将会大幅度提升大数据平台的整体性能。”