QingStor 对象存储发布了新版本的 Python SDK ,并已开源在 https://github.com/yunify/qingstor-sdk-python 。为说明新版本 Python SDK 和 旧版本 SDK 的区别与联系,本日志将会介绍新版本 Python SDK 的历史背景,变化革新和未来规划。在日志的最后,我们将会展示如何使用新版本的 Python SDK。
历史背景
在 QingStor 对象存储于 2016 年 1 月 6 日 开始公测时, 我们便在 qingcloud-sdk-python 中以 面向对象 形式的接口提供了 QingStor 对象存储的 Python SDK (为行文方便,我们在下文中将此 SDK 称为 旧版 Python SDK )。qingcloud-sdk-python 为 手动实现 的 SDK, 旨在提供 所有青云 QingCloud 服务 的访问。
变化革新
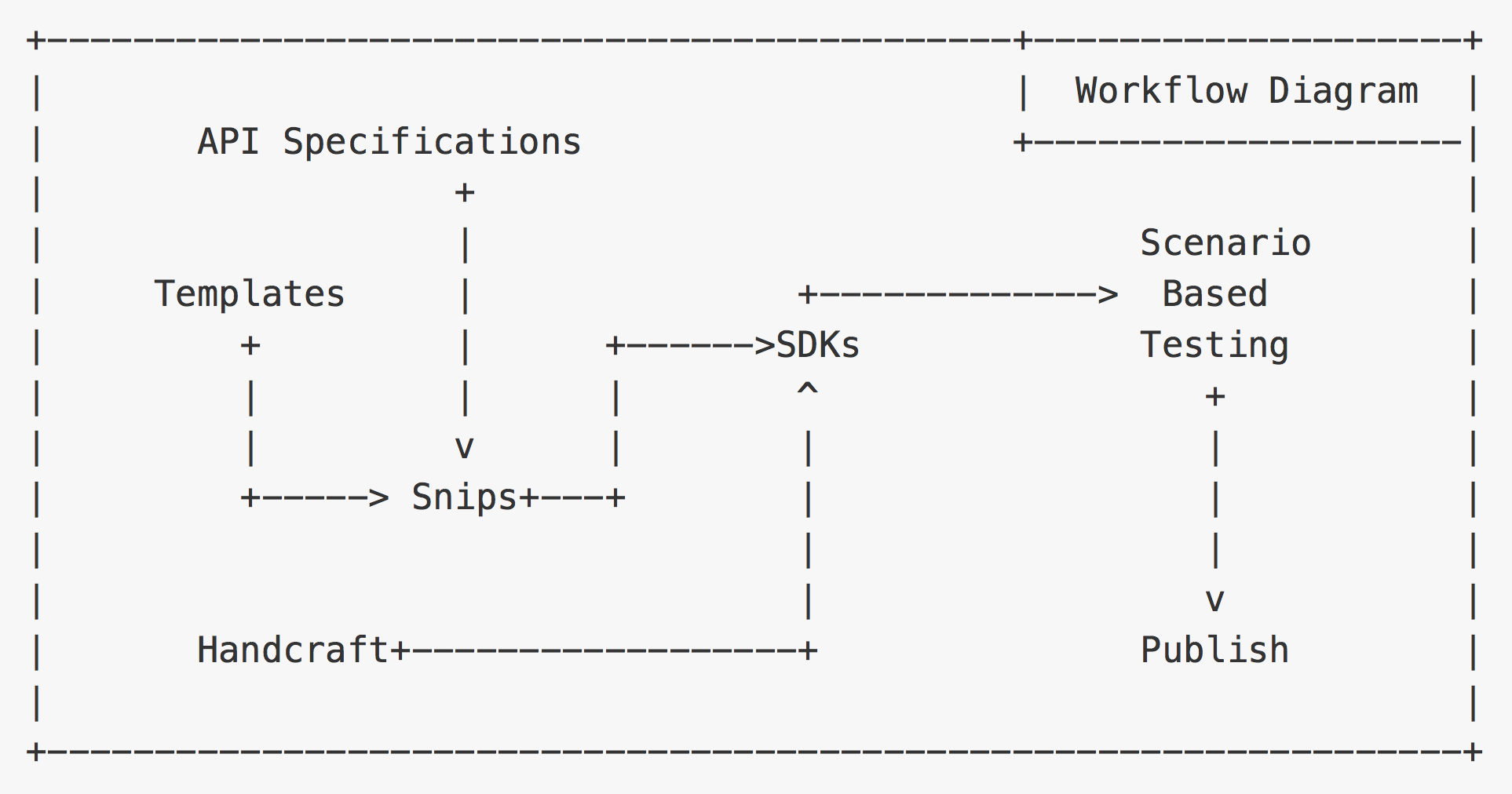
为了加快各语言 SDK 的开发效率,及减小各语言 SDK 的运维成本,我们决定将 SDK 的开 发及后期维护自动化。同时,考虑到移动端用户对空间的敏感,我们决定将 QingStor 对象存储的 SDK 与青云 QingCloud 的其它服务进行分离。
最终,我们于 2016 年 12 月 5 日 发布了 SDK 生成工具 Snips , 及使用 Snips 生成的六种语言 (Go, Ruby, JAVA, Swift, PHP, JS) 的 SDK, 如 qingstor-sdk-go 。
为了统一所有语言 SDK 的生成和维护, 我们于 2017 年 1 月 12 日 发布了 新版 Python SDK qingstor-sdk-python, (为行文方便,我们在下文中将此 SDK 称为 新版 Python SDK )。
- qingstor-sdk-python 不再与原有的 qingcloud-sdk-python 捆绑,可以灵活地应用于更多场景。
- qingstor-sdk-python 有着更完善的 API 设计,对开发者屏蔽了底层的细节,开发者无需关注具体的请求拼装,只需要调用对应的接口即可。
未来规划
考虑到所有语言 SDK 使用接口的统一,新版 Python SDK 的接口实现选择了 非面向对象 的形式, 即与 旧版 Python SDK 不兼容。
- 旧版 Python SDK 除修复 Bug 外,我们将不再维护。
- 新版 Python SDK 将由 QingStor 直接维护,享受到最及时的新功能增加, BUG 修复和技术支持。
如何使用新版 Python SDK
使用 SDK 之前请先在青云控制台申请 access key 。
准备工作
发起请求前首先建立需要初始化服务:
from qingstor.sdk.service.qingstor import QingStor
from qingstor.sdk.config import Config
config = Config('ACCESS_KEY_ID_EXAMPLE', 'SECRET_ACCESS_KEY_EXAMPLE')
service = QingStor(config)
初始化并创建 Bucket, 需要指定 Bucket 名称和所在 Zone:
bucket = qingstor.Bucket('test-bucket', 'sh1a')
output = bucket.put()
可以使用 dir(output) 的形式来获取全部可用的属性。特别的,output.headers 是一个包含返回中全部 header 的字典;如果请求失败, output.content 将会存储返回的错误信息。
Objects 操作
接下来将会展示创建,下载,删除一个 Object 的全过程:
创建 Object
with open('/tmp/sdk_bin') as f:
output = bucket.put_object(
'example_key', body=f
)
创建一个 Object 时,允许在body中传入一个 file like 对象,也支持直接传入一个字符串。上传一个比较大的 Object 时,建议使用 file 对象,避免将全部数据一次性读入内存。
下载 Object
output = bucket.get_object('example_key')
with open(local_path, "wb") as f:
for chunk in output.iter_content():
f.write(chunk)
下载一个 Object 时,建议使用 output.iter_content() 来获取文件内容。如果访问 output.content ,将会把全部数据一次性读入内存。
删除 Object
output = bucket.delete_object('example_key')
使用中遇到问题请在 项目 Issues 区 或者直接提交工单反馈。