QingStor 新增了 object copy 接口,使用此接口可将 QingStor 对象从源存储空间复制到目标存储空间,更详细的信息可 参考文档。
在 QingStor Web 界面上,我们也实现了对象拷贝、剪切和重命名的支持。
剪切和复制对象
在文件列表上右键 -> 剪切/复制

粘贴到目标文件夹
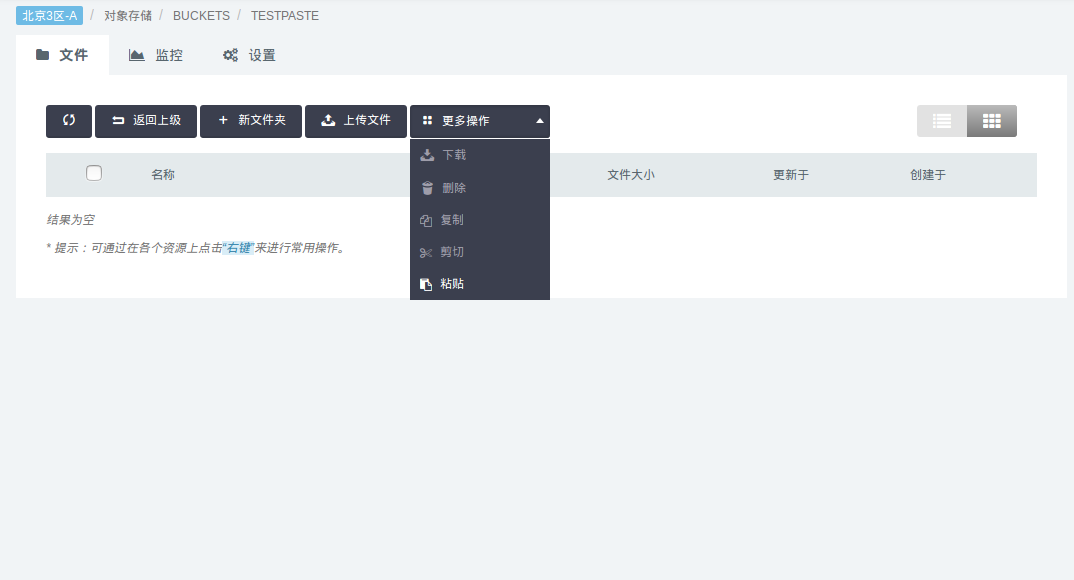
文件重命名
在文件列表上右键 -> 重命名

对话框里填写新文件名
QingStor 新增了 object copy 接口,使用此接口可将 QingStor 对象从源存储空间复制到目标存储空间,更详细的信息可 参考文档。
在 QingStor Web 界面上,我们也实现了对象拷贝、剪切和重命名的支持。
剪切和复制对象
在文件列表上右键 -> 剪切/复制
粘贴到目标文件夹
文件重命名
在文件列表上右键 -> 重命名
对话框里填写新文件名
qsctl 是青云对象存储服务的高级命令行工具。它提供了更强大的类 UNIX 命令,使管理对象存储的资源变得像管理本地资源一样方便。利用该工具,你可以快速地将数据在本地和 QingStor 对象存储之间迁移或同步。
支持命令
使用示例
列出存储空间 <mybucket> 下的所有对象:
$ qsctl ls qs://mybucket Directory test/ 2016-04-03 11:16:04 4 Bytes test1.txt 2016-04-03 11:16:04 4 Bytes test2.txt
同步 QingStor 目录到本地文件夹:
$ qsctl sync qs://mybucket/test/ test/ File 'test/README.md' written File 'test/commands.py' written
qsctl 的帮助和手册十分详细,查看 qsctl 的参数和简易教程,可以通过 -h 参数打印出来:
$ qsctl -h $ qsctl <command> -h
若要查看 qsctl 的详细手册和示例,可运行:
$ qsctl help $ qsctl <command> help
使用文档
qsctl 支持主流的操作系统(包括 Linux, Windows,以及 Mac),安装起来非常方便,使用 pip 工具即可,具体步骤可参考 官方文档。
跨源资源共享 (Cross-Origin Resource Sharing,简称 CORS) 是 HTML5 提供的标准跨源解决方案,具体可以参考 W3C CORS规范 。
QingStor 已经支持 CORS ,可以允许您对 QingStor 下的存储空间 (Bucket) 进行 CORS 规则的配置, 从而可以创建直接与 QingStor 进行富交互的 web application,以及限制源对您在 QingStor 中资源的访问,参考 QingStor Bucket CORS 。
典型场景和示例
当浏览器端使用 AJAX 直接访问 QingStor 的数据时,则需要利用 CORS 来实现跨源浏览器与 QingStor 直接通信。
例如,网站的某些静态图片资源存储在 QingStor 的 “images” 这个 bucket 中。如果网站想利用 JavaScript AJAX 取回或者上传图片。当向 bucket 直接发起 GET, POST 请求时,是不被允许的。此时则需要设置 CORS 的规则。
设置示例
主要配置项:
操作流程:

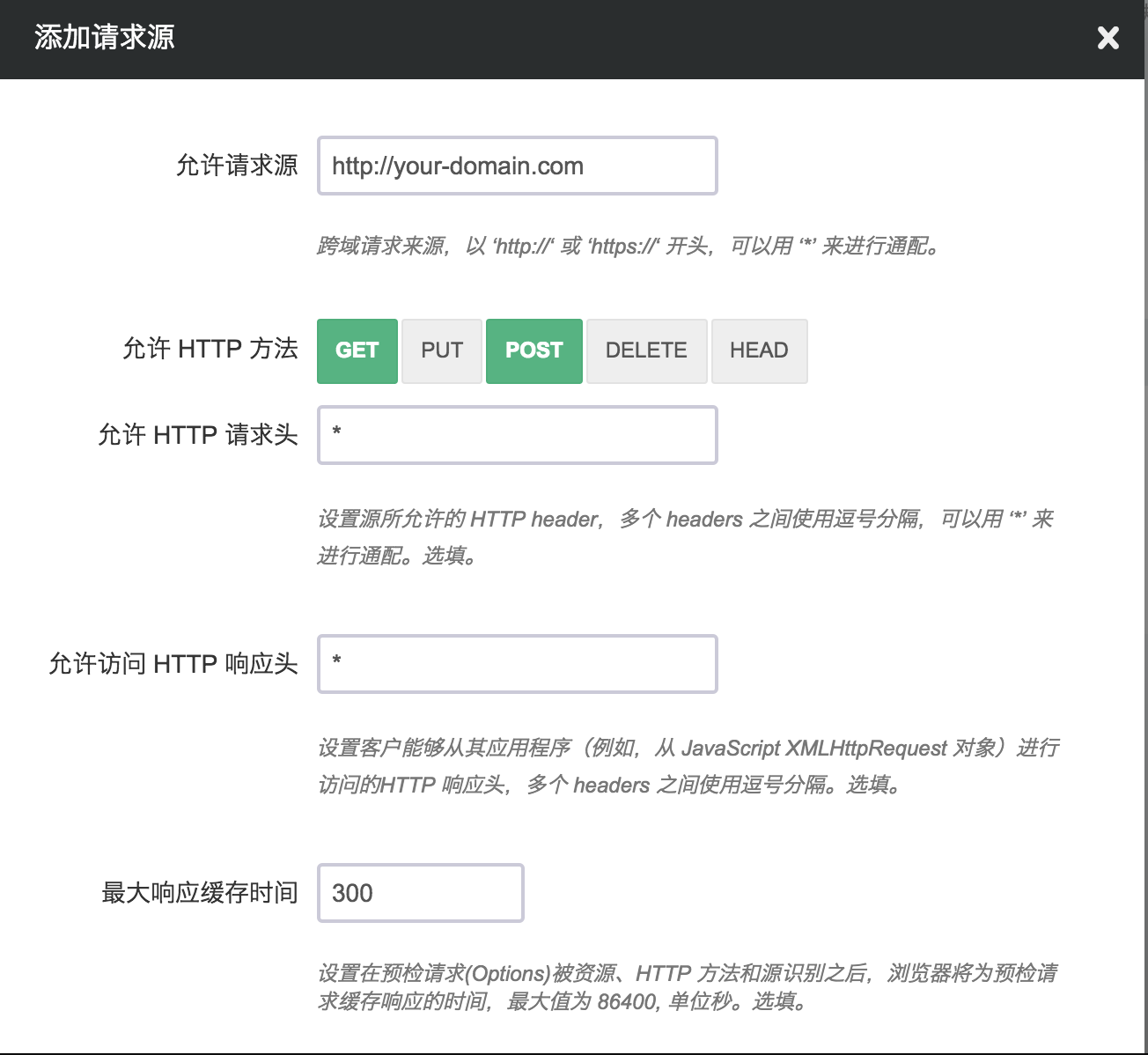

以上示例配置, 将使您从 http://your-domain.com 发出的对 QingStor bucket 的 AJAX 跨源 GET, POST 请求成功执行,同时缓存预检请求300s,并能从 AJAX 的返回结果中访问到任意的 HTTP header。

2016 年 9 月 13 日,QingStor 对象存储服务(Object Storage)正式启动商用,同时开放的还有 CDN 加速服务,所有青云QingCloud 用户可以在北京 3 区(PEK3)使用上述两项服务。商用的第一个月为缓冲期,缓冲期结束后( 10 月 13 日)开始计费。立即体验
QingStor 对象存储于今年 1 月 8 日启动公测,随后进行了为期 8 个月的试运行。在公测期间,用户在 QingStor 对象存储累计上传文件数量超过 100 亿,容量达到 1PB ,文件类型包括静态网页、音频、视频、文档、日志、映像等。
在大量公有云用户多样化的应用场景中,QingStor 对象存储在性能(高并发)、可用性、稳定性等方面得到了充分的验证。同时,QingStor 对象存储已经在借贷宝、泰康人寿等多套私有云生产环境中部署上线,承担了重要的存储引擎角色,为客户的互联网业务提供强大助力。
QingStor 对象存储特性介绍
QingStor 对象存储为用户提供可无限扩展的通用数据存储服务,具有安全可靠、简单易用、高性能、低成本等特点。其突出优势概括如下:
QingStor 对象存储功能介绍
QingStor 对象存储生态
QingStor 对象存储基础应用场景
场景一:海量通用文件存储
QingStor 对象存储服务提供了安全、可靠的数据存储服务,适用于静态网页、图片、音视频、日志、映像等各种类型文件的存储,支持用户通过控制台、API、SDK 等各种方式进行读写。同时 QingStor 对象存储系统可无限水平扩展,且在存储容量水平扩展时,数据存取的性能线性提升。相较于块存储,可以更好地满足企业海量数据的存储和访问需求,同时节约了大量的存储成本。
场景二: 数据分析&挖掘:
QingStor 对象存储作为海量数据存储池,将会与 QingCloud 平台上的计算资源紧密整合,尤其是 QingCloud 大数据平台(如 Hadoop、Spark、 Storm 等),从而实现高性能、低成本的数据分析与挖掘,提升企业数据价值。
场景三: 互联网应用加速:
QingCloud 精选主流 CDN 厂商优质节点,全面覆盖各运营商,无盲区;自动选择离用户最近的边缘节点,使得数据的传输速度最优化。为互联网应用的图片、音视频以及应用分发提供最佳的用户体验。
场景四: 数据备份:
QingStor 对象存储服务通过兼容基于 AWS S3 API 构建的工具与服务,支持主流的备份软件,结合快速的数据存取性能、高度的服务可靠性和数据安全性、细粒度的权限控制及简单易用的接口,向用户提供更高性能、更可靠、更低成本的数据备份方案,帮助企业节约本地存储成本、维护成本和人力资源成本。
QingStor 对象存储快速上手
QingCloud 用户可以在控制台选择北京3区(PEK3)通过图形化界面来创建存储空间( Bucket ) 并上传文件(具体操作请点击阅读原文查看),同时我们推荐大家通过 API、SDK 以及命令行工具来管理和使用 QingStor 对象存储。
QingStor 对象存储 12 个月免费用
QingStor 对象存储将从存储容量、流量、API 请求数三个维度进行阶梯计费,并为用户创建的第 1 个存储空间(Bucket)提供 12 个月赠送套餐,从用户创建的第 1 个存储空间之日算起,在未来 12 个月免费赠送:
PS:免费政策只对用户创建的第 1 个存储空间有效。当 12 个月的免费试用过期或使用量超过了免费限额,按照资费标准按需支付。
更多详情请见《QingStor 指南》。
CDN 的全称是 Content Delivery Network,即内容分发网络。主要作用是给网站的资源请求加速,资源范围包含图片、视频等静态资源。其基本思路是在网络各处放置节点服务器,在现有的互联网基础之上构建一层智能虚拟网络。这些节点服务器会按照一定的缓存策略存储网站的业务内容,当有用户向网站业务发起资源请求时,CDN 系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。
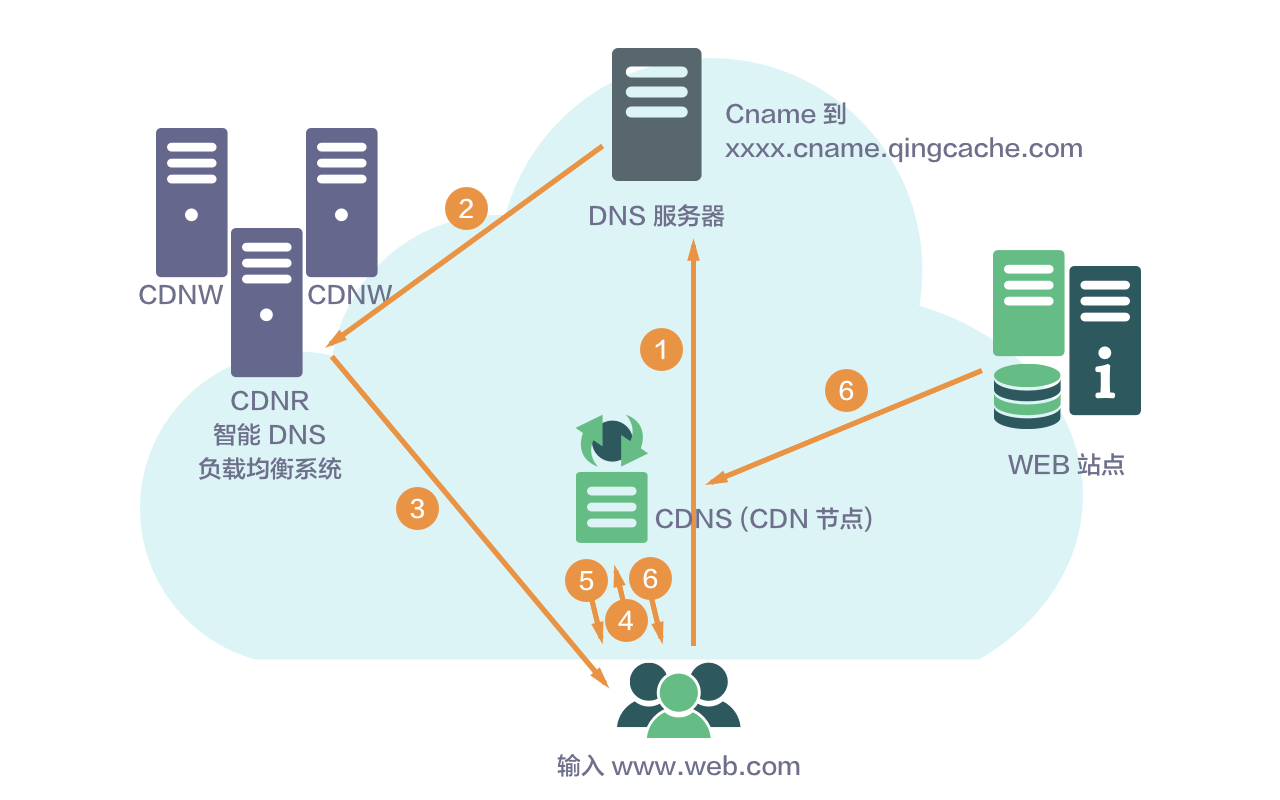
QingCloud CDN 并不完全是由 QingCloud 自建完整的 CDN,而是通过精选网宿、蓝汛等主流 CDN 厂商优质节点,全面覆盖各运营商,达到无网络盲区。QingCloud CDN 服务可自动选择离用户最近的第三方节点,使得数据的上传和下载速度得到最优化。
用户可以自定义配置 QingCloud CDN 缓存策略规则、访问规则、防盗链、内容刷新等配置,灵活使用 CDN。并提供访问省份、访问文件次数、流量、带宽等丰富的监控统计,帮助用户时刻了解 CDN 使用情况。
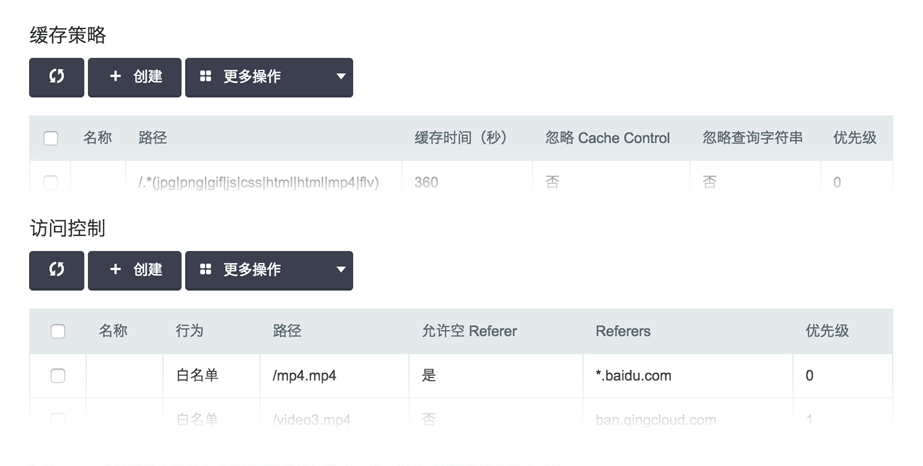
QingCloud CDN 可以在以下几个应用场景中有效提升互联网业务中的访问效率:
QingCloud CDN 配合 QingStor™ 对象存储服务使用,可实现图片、音视频、文档、日志等文件的请求加速,从而获得最佳访问体验。此外,用户在使用 QingStor™ 对象存储服务对源站资源进行存储后,还可在 QingCloud CDN 加速服务中选择 QingStor™ 作为源站,这样做也能够提升 CDN 的回源性能。
QingCloud CDN 服务将根据流量计费,每日以用户域名为单位统计流量使用情况,再乘以单价得出每日的计费结果,进行扣费。计费时间将按照自然日统计,每日凌晨期间进行扣费。另外,QingCloud CDN 提供了多种阶梯定价供用户灵活选用,用户可以根据业务情况按需付费。
QingCloud CDN 服务商用缓冲期为一个月,缓冲期结束后(10月13日凌晨)开始正式计费。
| 范围 | HTTP 价格 | HTTPS 价格 |
|---|---|---|
| 0TB ~ 1TB | ¥ 0.35 / GB | ¥ 0.42 / GB |
| 1TB ~ 10TB | ¥ 0.33 / GB | ¥ 0.40 / GB |
| 10TB ~ 50TB | ¥ 0.3 / GB | ¥ 0.36 / GB |
| 50TB ~ 100TB | ¥ 0.27 / GB | ¥ 0.32 / GB |
| >100TB | ¥ 0.25 / GB | ¥ 0.30 / GB |
更多详情请参看《CDN 服务指南》。
HBase 是一个开源的、分布式的、数据多版本的,列式存储的 nosql数据库。依托 Hadoop 的分布式文件系统 HDFS 作为底层存储, 能够为数十亿行数百万列的海量数据表提供随机、实时的读写访问。 青云提供的 HBase 集群服务包含:HBase 数据库服务、HDFS 分布式文件系统、Phoenix 查询引擎。压缩格式方面支持 GZIP、BZIP2、LZO、SNAPPY,可自行在应用中指定。 关于 HBase 更多的详细信息,可参阅HBase 官方文档,关于 Phoenix 查询引擎的详细信息,可参阅 Phoenix 官方网站 。
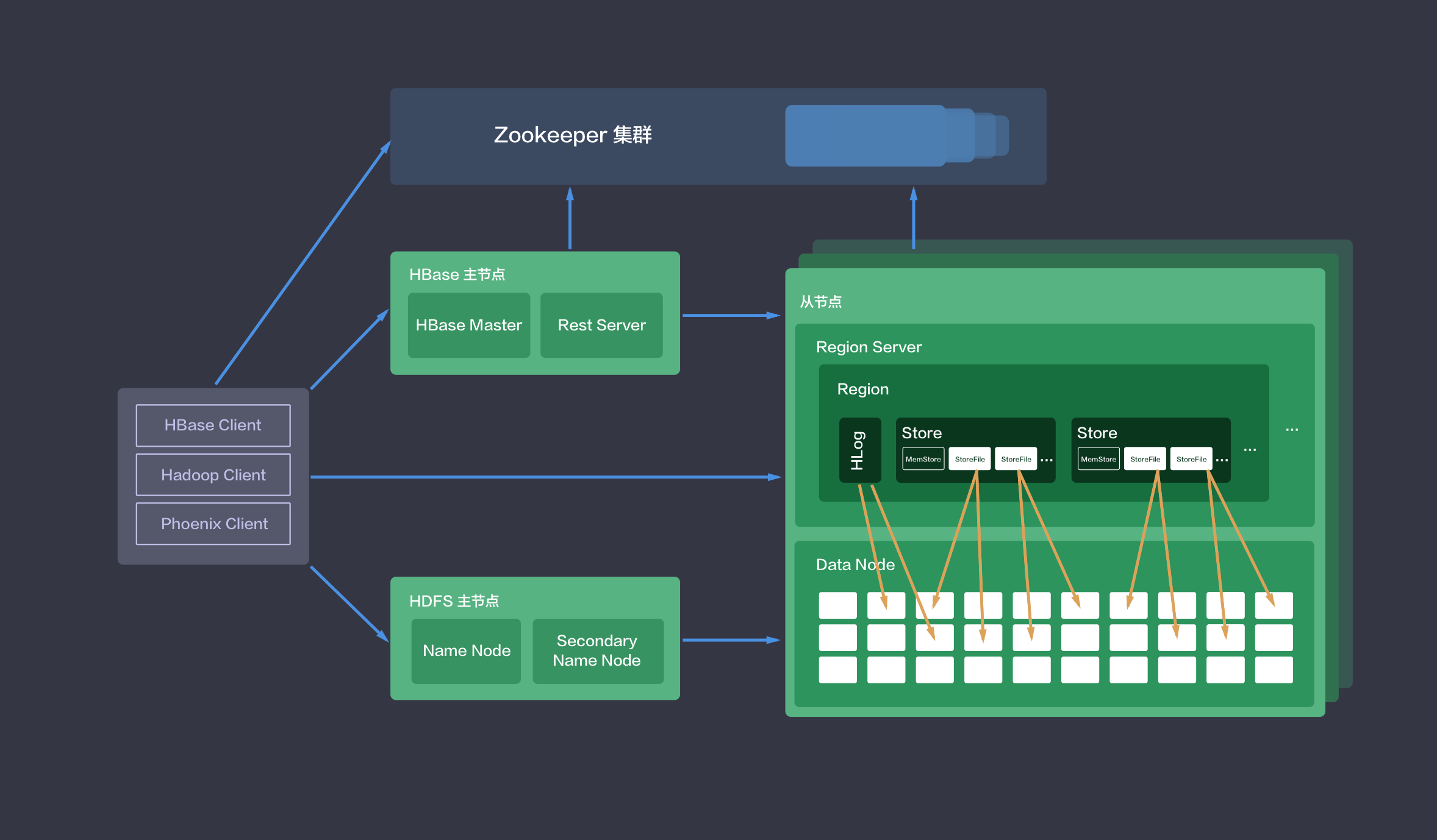
与 Hadoop 一样,HBase 集群采用的是 master/slave 架构,青云提供的 HBase 集群服务还包括在线伸缩、监控告警、配置修改等功能,帮助您更好地管理集群。 如下图所示,青云的 HBase 集群分三种节点类型:主节点 (HBase Master 和 HDFS NameNode),从节点 (HBase RegionServer 和 HDFS DataNode) 和客户端节点 (HBase Client)。 用户在HBase 客户端可通过HBase Shell、Java API(本地或MapReduce)、Rest API 或其他工具来访问HBase。 若需要使用除java外的其他语言时,可在客户端节点 (HBase Client)自行启动 Thrift Server 以供支持。
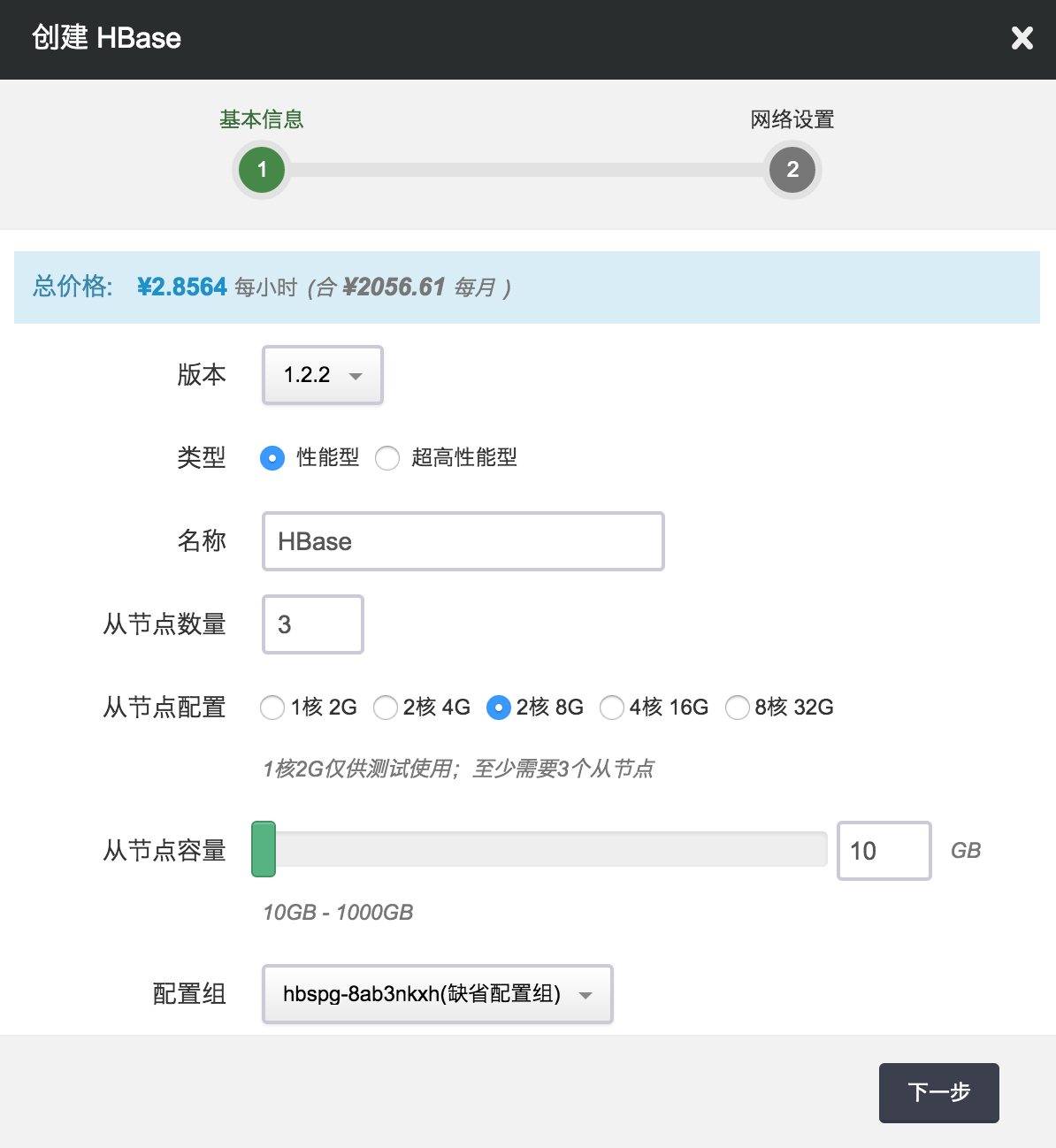
另外,QingCloud 的 HBase 服务还提供:
增加节点:您可以在 HBase 详情页点击“新增节点”按钮增加从节点,可以对每个新增节点指定 IP 或选择自动分配。
删除节点:您可以在 HBase 详情页选中需要删除的从节点,然后点击“删除”按钮,只能一次删除一个,并且必须等到上个节点删除后且 decommission 结束才能删除下一个节点,否则数据会丢失。 青云 HBase 集群在此操作时会先迁移 region 再复制数据,确保用户业务不受影响。
纵向伸缩:由于不同类节点压力并不同,所以青云 HBase 支持对 HBase Master Node 主节点、HDFS Name Node 主节点 和 HBase 从节点分别进行纵向伸缩。
我们对 HBase 集群的每个节点提供了资源的监控和告警服务,包括 CPU 使用率、内存使用率、硬盘使用率等。 同时,HBase 和 HDFS 提供了丰富的监控信息。如果需要通过公网访问这些信息您需要先申请一个公网 IP 绑定在路由器上,在路由器上设置端口转发,同时打开防火墙相应的下行端口。 HBase Master 默认端口16010,HDFS Name Node 默认端口是50070。为方便查看HBase UI,请参考 VPN 隧道指南 配置VPN,VPN 建立后可查看下述界面。
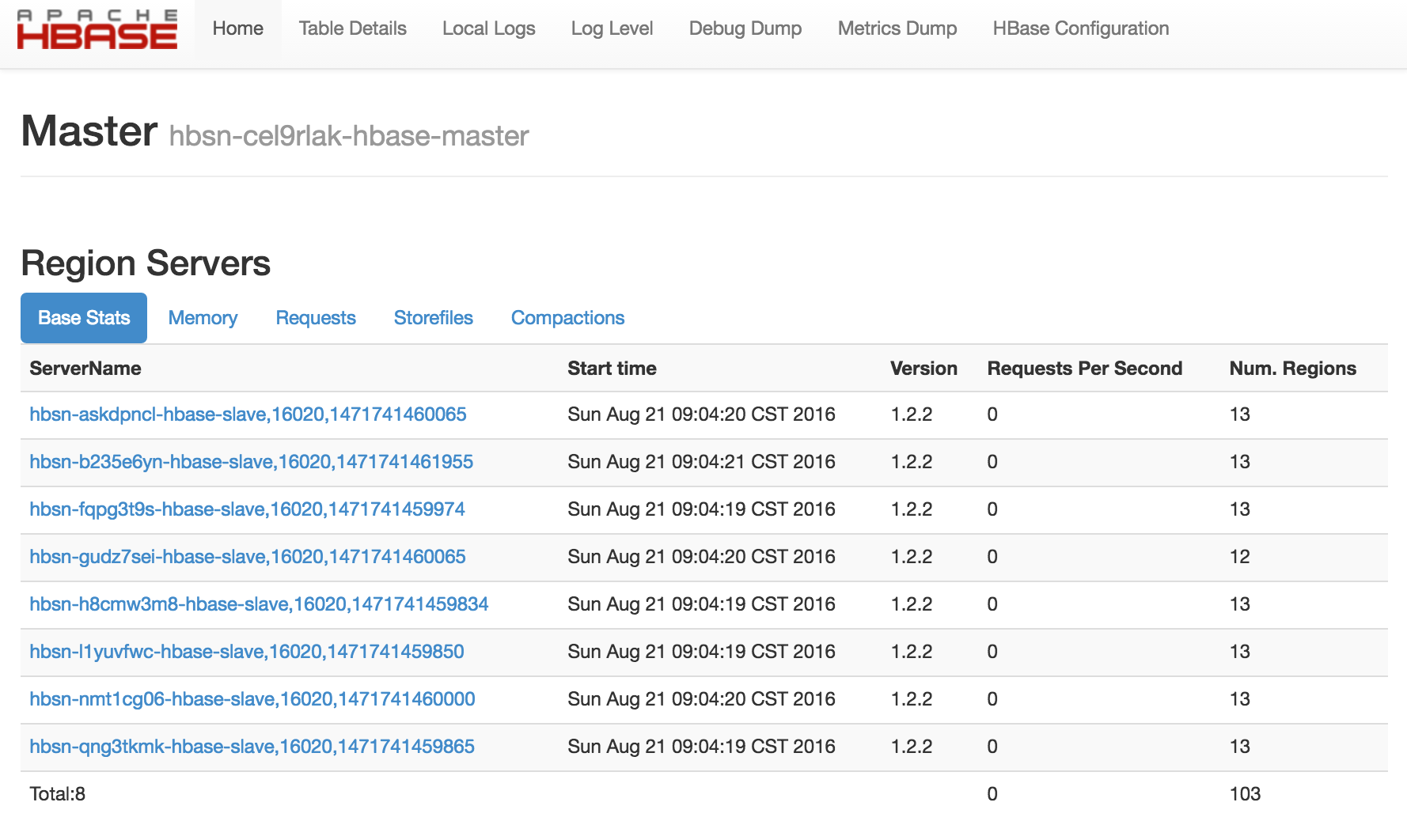
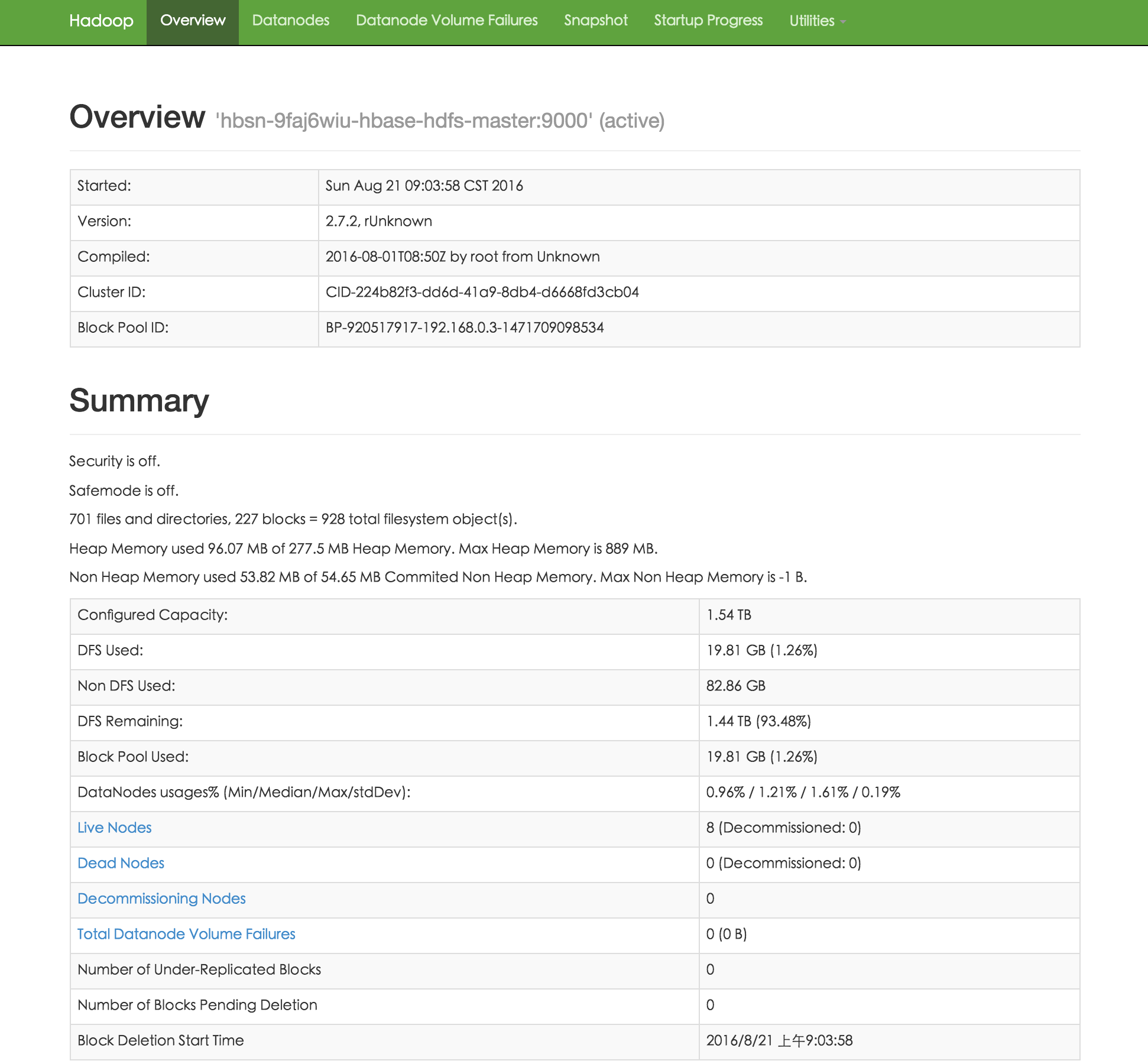
为了帮助用户更好的管理和维护 HBase 集群,我们提供了部分针对 HBase 服务的监控,包括:
我们通过 HBase 配置组来管理 HBase 服务的配置。HBase 服务和 HBase 配置组是解耦的,您可以创建多个独立的配置组,并应用到不同的 HBase 服务。
关于集群服务的可用性测试请参看《HBase 使用指南》的HBase 集群测试部分。


当性能型硬盘从一台主机解绑并绑定到另一台主机时,可能会触发数据迁移导致绑定时间很长。我们对这个绑定速度进行了优化,现在解绑并重新绑定的时间能缩短到秒级,同时不随数据量大小而变化。
Storm 是一个开源的分布式实时计算系统,通常被比作"实时的 Hadoop"。Storm 为实时计算提供了一些简单优美的原语,支持多种编程语言,并内建流式窗口 API 及分布式缓存 API,极大简化了流式数据处理过程。Storm 不仅高可靠、易扩展,而且处理速度极快,每个计算节点每秒能处理上百万条元组信息(Tuple),因此常被用于实时分析、在线机器学习、连续计算、分布式 RPC、ETL 等。 关于 Storm 更多的详细信息,请参阅 Storm 官方网站 。
青云的 Storm 集群包括如下五种节点类型:
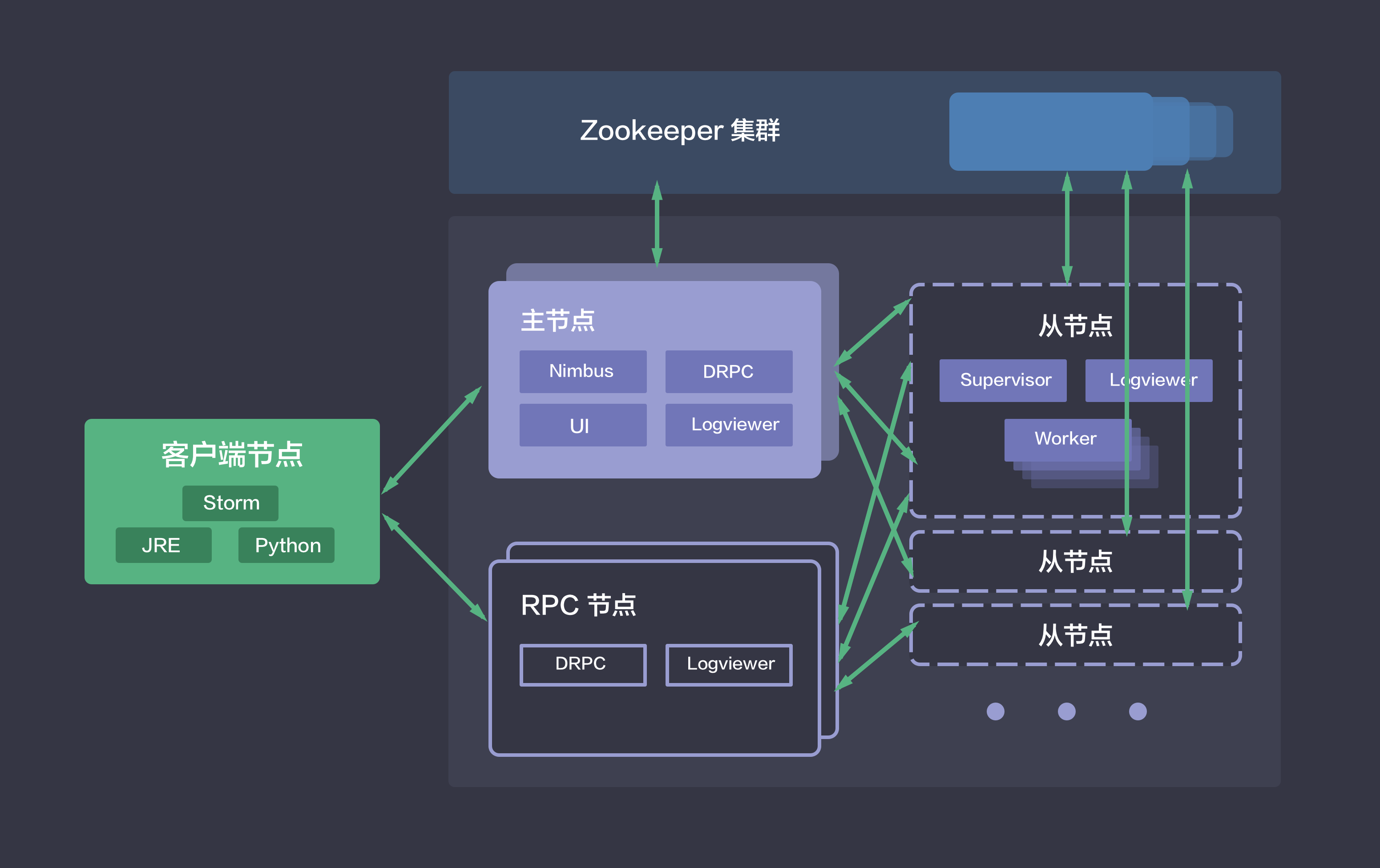
另外,青云的 Storm 服务还提供了在线伸缩和监控告警功能:
增加节点:当您需要横向扩展集群规模时,您可以在 Storm 详细页点击“新增节点”按钮增加主节点、从节点或 RPC 节点,每个新增节点在私有网络中的 IP 可以手动指定或选择自动分配。
删除节点:当您不需要集群中的某些节点时,您可以在 Storm 详细页选中需要删除的节点,然后点“删除”按钮,以在线缩减集群规模。
纵向伸缩:由于不同类节点压力并不同,所以青云 Storm 支持对 主节点、从节点 和 RPC 节点分别进行纵向伸缩。通常情况下主节点和 RPC 节点的压力都不会太大,运行 worker 进程的从节点的配置一般更高些。
我们对 Storm 集群的每个节点提供了资源的监控和告警服务,包括 CPU 使用率、内存使用率、硬盘使用率等,以帮助用户更好的管理和维护 Storm 集群。 同时,Storm 主节点上运行的 Storm UI 服务提供了丰富的集群监控信息,默认端口为8080。 此外,青云提供的 Storm 集群还在各个节点上运行了 Logviewer 服务,该服务允许用户访问各个节点上的日志。拨入到 VPN 网络后,可以访问以下 URL 来浏览 Storm UI 及节点日志:
例如:
我们通过 Storm 配置组来管理 Storm 服务的配置。Storm 服务和 Storm 配置组是解耦的,您可以创建多个独立的配置组,并应用到不同的 Storm 服务。
更多详情请参看《Storm 用户指南》。
Elasticsearch 是一个分布式的全文搜索引擎,提供 RESTful 接口,以及近实时的索引、搜索、分析功能,基于 Lucene 构建,主要以 Java 开发,以 Apache License 开源。 更多详细文档请参看 Elasticsearch 官方网站 。
在青云上,您可以很方便的创建和管理一个 Elasticsearch 集群。青云的 Elasticsearch 集群支持横向与纵向、完全意义上的在线伸缩,即 Elasticsearch 的在线伸缩对客户端是透明的,用户的业务连续性不会因此而中断。另外我们还提供了监控告警等功能来帮助您更好的管理集群。集群将运行于私有网络内,结合青云提供的高性能硬盘,在保障高性能的同时兼顾您的数据安全。
增加节点
当 Elasticsearch 需增加节点以应付数据以及客户端逐步增多带来的压力,您可以在 Elasticsearch 详细页点击“新增节点”按钮。 同样,您可以对每个新增节点指定 IP 或选择自动分配。
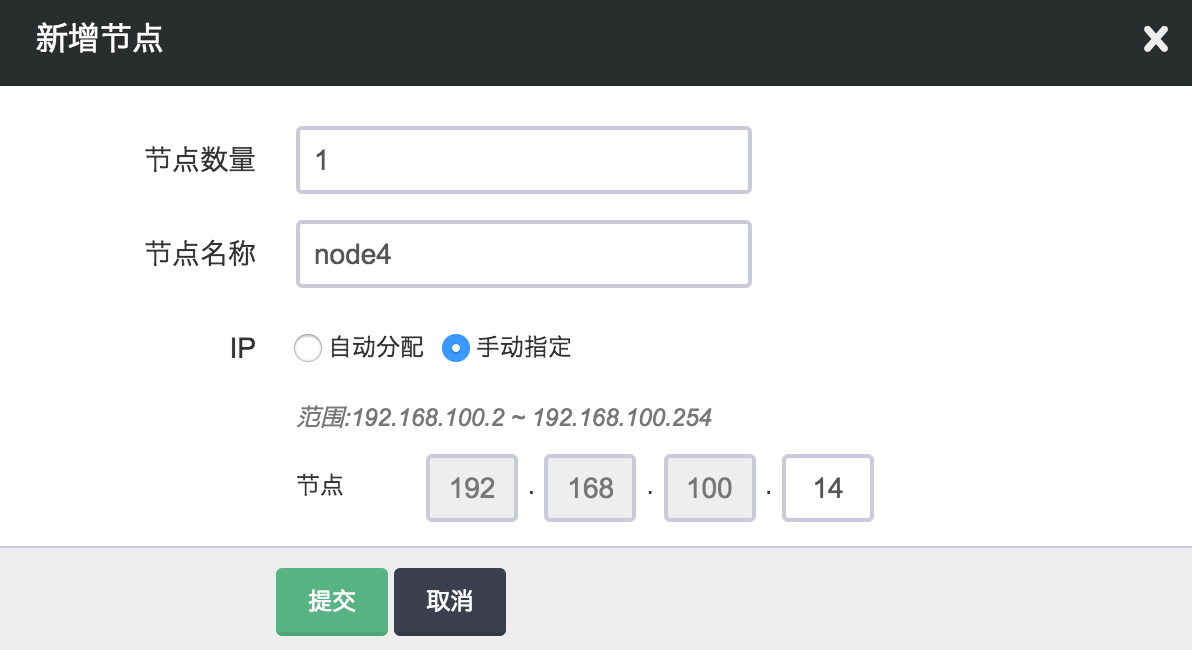
删除节点
如果 Elasticsearch 集群的节点超过需求,您也可以在 Elasticsearch 详请页选中需要删除的节点,然后点“删除”按钮删除节点,以节省资源和费用。 删除节点的时候可能会触发数据迁移,所以一次只能删除一个节点。删除节点不影响集群服务。
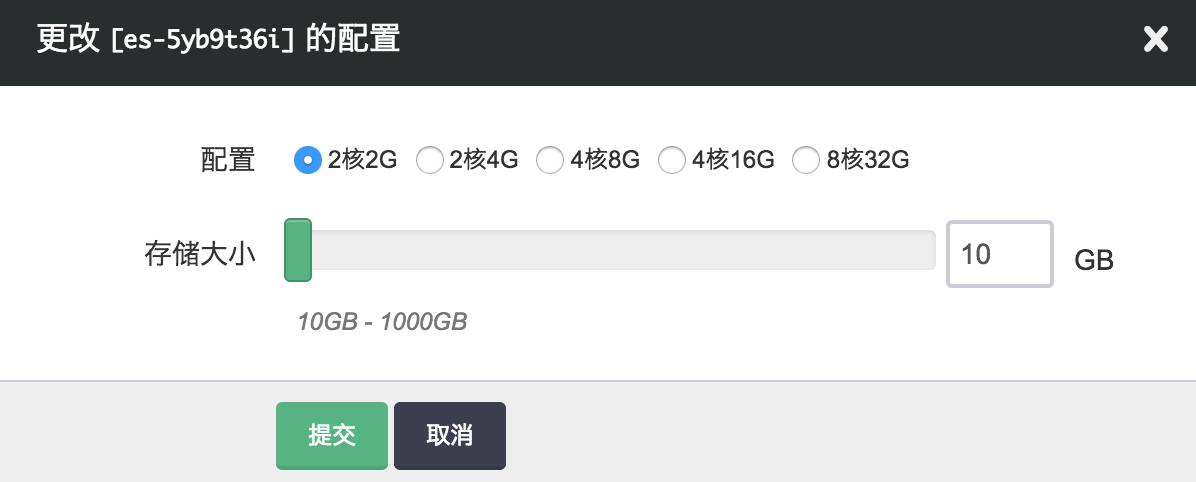
纵向伸缩
由于 Elasticsearch 会充分利用内存来提升查询效率,所以当业务存放在 Elasticsearch 里的数据量增大到一定程度的时候,不可避免需要纵向扩容每个节点的内存。反之,如果节点的 CPU、内存使用并不大,可以降低配置。同时 Elasticsearch 的数据会落到磁盘上,如果磁盘空间不够也需要扩容,不过磁盘不支持缩小容量。 磁盘扩容的时候无需重启节点,不影响服务,但CPU、内存的伸缩需要重启节点,会逐台重启节点,不影响集群的整体功能,但也可能影响对某个节点的请求。
我们提供了监控和告警服务,以帮助用户更好的管理和维护运行中的 Elasticsearch 集群。
监控服务
对每个节点提供了资源监控,包括 CPU 使用率、内存使用率、硬盘使用率等。
告警服务
我们对每个节点 Elasticsearch 服务是否正常进行监控并设置告警策略,一旦某个节点 Elasticsearch 服务发生异常就进行告警,并发送短信和邮件通知给用户。
虽然单节点出现异常并不影响集群的正常服务,但越早发现问题并及时解决是维护整个集群长期正常运行的最佳实践。
更多使用文档及注意事项请参看“Elasticsearch指南”。